WeTransfer started scrappy. A Dutch company, born in a small studio that built easy-to-use tools for their internal needs. In 2009, the easiest way to send large files was to put them on a drive and hand them to a courier. Email had (and still has) size limits, and running your own on-prem FTP server is not something that every creative studio is looking to take on. So, a small group from the studio’s IT and design took it on themselves to build a simple way to share large files with their clients; upload a file, and share a link that allowed on-demand downloads.
While the first version of the product was designed for our internal use case of sharing files with clients, our clients loved the experience and wanted to use it with their clients. This built-in virality caused the customer base to grow rapidly, and suddenly the initial product - built in Flash - felt more like a proof of concept than a production system. Basic considerations for managing user data, setting quotas, handling file size limits, controlling access, and providing support hadn’t been planned out. There was a SQL database backing transfer and files that used INTs for indices and was barreling towards index exhaustion, with no strategy in place for schema revisions or data migration. Scaling up that fast highlighted all the problems that weren’t solved when WeTransfer first launched. Seeing both the problems and the opportunity, the company hired an engineering team to build the architecture and core capabilities - and the first rebuild was underway.
For many companies this is what success looks like: customers adopt your product, usage grows, and you start building as quickly as you can to scale up, deliver key features, and keep systems running. Building in the cloud gave us so many levers - adding compute, adding storage, routing requests through CloudFront - that the team was able to focus on solving customer problems and not the hardware constraints.
But this ease of use isn’t free. When a solution involves scaling cloud services up, it’s no longer just an engineering solution, but a business decision. We saw our costs grow. We realized the environmental impact of our growth. It forced us to reflect on how and what we were building our products. What choices were we making that we would need to revisit if growth continued? What were the true costs we were incurring and how would those scale over time?
As a company that cares about people, the planet, and its place in the world, we had to evolve our approach to cloud consumption. And so, our journey started with a clear goal of reducing our carbon footprint while continuing to grow a profitable business. To become a frugal consumer of the cloud, with our values aligned to our technology. I joined a few months into this journey, in February 2021, after WeTransfer had just recently received its B Corp certification.
My start in embedded systems
My story starts before the cloud. My first job out of university was for a small company building reference kits for digital audio players. Back then OEMs and ODMs were jumping on the MP3 train as the iPod hadn’t yet come along and established itself as the sole player in the space. It was an emerging space and there was a ton of energy in both software and in embedded systems.
The devices we worked on were really constrained – less than 50K of RAM on a 74MHz SOC. There was no virtual memory and no variable clock speed. Resources had to be carefully budgeted to ensure that we never ran out. Success was also very simple: play real time audio. It had to work 100% of the time. There was no value in getting 90% of the way there; nobody wants an MP3 player where all the songs skip.
All of our builds started with a SOC we had selected, which provided the foundation for compute, memory, and I/O. This SOC was then integrated into a modular reference board, which provided peripherals such as display, network, storage, and input controls.
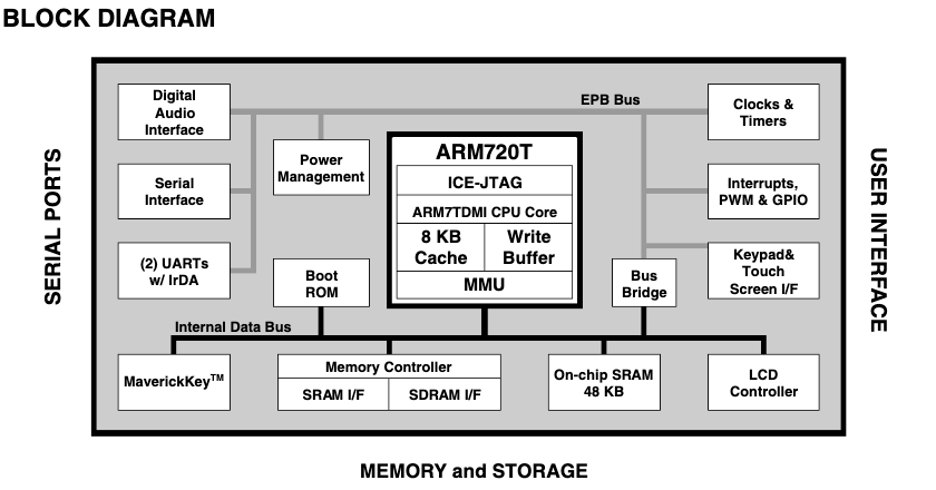

Each new device I’d work on had a different set of performance limitations, usually around I/O, and every time I’d have to think through my options and approach. What would it take to write this driver in assembly? What about unrolling loops? Cache alignment? Can I rework the thread scheduler to have a better balance between round robin or pure priority based? What more can I do to make this system efficient?
The deeper I dug in, the more I became familiar with the hardware, compiler, and runtime system capabilities. I’d see other places where I could save a bit of memory or reduce CPU consumption, like removing a buffer copy in file I/O. I’d keep a tab on ways to improve efficiency of our software for the next device we’d work on and the new hardware configuration and resulting challenges it may bring.
It was a crash course in working with embedded systems, one that set me on the path of building software for target hardware. It pushed me to find the balance between efficiency and user experience in building great products. It’s an experience I’ve carried forward with me. The sense that efficiency is a critical part of software engineering. It’s hard for me to consider delivering software without fully understanding resource consumption.
A cultural shift to reduce digital waste
When I joined WeTransfer, many of the constraints that had shaped my prior experiences were removed - teams were focused on the problem they were solving – and it was otherworldly to me. We had a scenario where the right solution was to create a second read replica of an RDS database during some refactoring work. In no prior world I’d lived in has just add 50% more been an option.
This ease was an exceptional thing. It let us move quickly. We built fast, learned fast, and failed fast - for a cost. The cloud replaced the system level constraints that put pressure on engineering, and replaced them with financial impact that put pressure on our cost of goods sold (COGS). CPU and memory efficiency were measured in dollars. From a cost perspective, cloud services and headcount dwarfed all other expenses. From a carbon emissions perspective, cloud service consumption was the highest impact part of our business by far.
Internally we saw the costs we were incurring were a reasonable proxy for the carbon emissions we were generating, and aligned on a goal of reducing digital waste. Digital waste was the resources we consumed that yielded no customer value, that then cost us money, and in turn generated carbon impact. The server that was running on our behalf when it didn’t need to be, or the extra files we didn’t need to store. We could measure these on a daily basis by looking at our costs in tools like Cost Explorer. And this approach gave us a good view as to what our carbon impact would be when we analyzed that on a quarterly and annual basis.
Our mission to reduce digital waste kept us honest to only consuming what resources we needed. It allowed our inherent judgment as to what is wasteful to guide investments, rather than the analytical skills applied when focusing on optimization. And it gave a clear mindset in engineering around how to ease pressure on the P&L.
The importance of revisiting past decisions
The global pandemic in 2020 and the growth of the creator economy led to another surge in usage and growth of our business. While our business model continued to thrive, the real dollars associated with cloud service consumption and the resulting environmental impact moved into focus. It was at this time that we had some of our earliest conversations with AWS around our costs and carbon impact. In the absence of consistent internal measures, it gave us a chance to learn from data AWS pulled around our usage and impact - data like average utilization of our reserved instances to places where we were routing traffic inefficiently and generating more work at higher costs.
These conversations highlighted just how much certain patterns we had adopted early on hadn’t scaled with our business. For example, we used S3 Standard for all files. This was great early on, when all files had a lifetime of 7 days on our platform. Over time we added scenarios where files would persist for 90 or 365 days with infrequent access over time. This new usage pattern aligned well with some of the storage tiers supported in S3 and in early 2022 we added support for Glacier Instant Retrieval (GIR) and started tiering files into glacier after 30 days. With GIR, we paid a lower storage cost that far outweighed the modest increase in access costs we saw, and over time were able to see a 78% reduction in our carbon footprint for storage with no degradation in the user experience.
On the compute side, we had been using fixed reservations. Early on, this was fine as the compute requirements were both small in comparison to storage and not variable. We also primarily used storage, and our compute costs were normally 1/5th of our storage costs, so they didn’t receive as much attention.
As we grew, we historically just upped our consumption – increasing our resource reservations, moving to larger instance sizes, and trying to size above the largest loads we had ever seen so we’d never hit resource exhaustion. Years of being reactive had led us to hold significantly more capacity than we needed on most days, especially as our awareness of seasonal usage patterns and weekend usage grew. In the end, due to scaling up during times of virality and incidents, we were holding almost 4x more compute than we needed. Waste that didn’t align with our values.
There are solutions for this. For example, cluster autoscaling allowed us to move away from fixed reservations and specify ranges, allowing the autoscaler to adjust the number of running nodes based on workload. Moving to the cluster autoscaler in 2022 wasn’t a simple change – we had to engage all teams, provide guidance on how to set reservations and limits and how to iterate over time, but the amount of unused reserved capacity we were paying for was clearly far beyond what we needed.
You can’t measure what you don’t see
The next step was to build on our progress and grow our understanding of how the rest of our systems were behaving. We had a fragmented observability stack that was inconsistently used across our services, making it difficult for engineers to observe and monitor their services. Some lacked design documentation, and historical knowledge had been lost over the years as people left the company. Because we didn’t know what we didn’t know, when we started the process of adding observability, we often observed unexpected behaviors, and then worked our way back to long-lived design choices and assumptions in software that no longer made sense.
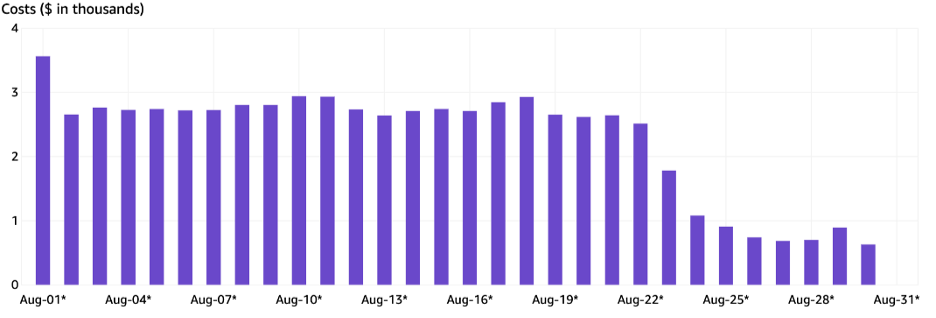
A great example of this happened in 2022. When people send files with WeTransfer, we hold them in S3 for a few days - at the time we defaulted to 7 - and after that we expire the transfer and delete the files. A new member on our team, Alan Pich, was heavily investing in observability after our prior reliability issues and storage overruns and noticed an odd thing.
No transfers were ever deleted on day 7. Sometimes it was day 8, sometimes it was 9, but never at 7 days. Given how our storage costs worked, the extra day or two was a meaningful expense - we were storing files that our users no longer needed, that we had marked for deletion, for as much as 20% longer than we needed to. That additional storage was a clear example of waste - no user value, no need, and a significant cost.
Working backwards from observability - adding to an existing system then trying to understand why the system behaves a certain way - is always more painful. It is the guaranteed way to get any engineer to say “that shouldn’t be doing that”, as monitors let you see the true behavior of your code rather than the intended behavior in the design. In our case, as we dug in on how we managed deletions, we quite embarrassingly found the one line of code where many years ago, someone had introduced a 36-hour delay in the deletion task. It turns out that at some prior point, deletions were sometimes triggered prematurely, and in an effort to address that a delay had been written very deep in the storage layer to give users enough time to report the issue and a support agent the ability to recover a transfer.

We hadn’t used that capability in years. No support agent knew it existed. And as we unwound that delay we found it was roughly 16% of our storage costs. While this sounds absurd on the surface, it’s the result of never having constraints on our costs and growth. The result of years of growth funded by investment without the appropriate monitors in place. Nobody was looking for how that delay performed over time because our focus was, and had to be, on how to continue serving the surge of customers coming in.
This moment was empowering. As a team, the extent of what we were missing with our lack of observability became very clear. The business impact of changes we could make by observing and monitoring usage was obvious. What was once completely untracked had become tracked by the business due to our costs growing, then seen by the team as we added observability, and finally became actionable.
It also made clear that not every step forward had to be a huge investment. Later that year an engineer started asking questions around storage when a customer downgrades from a paid plan to free. With a bit of analysis, we found another few PBs of leaked data that had never been cleaned up - storage that we were paying for that would never be accessed by customers. The team’s curiosity had been sparked.
Observability: Our canary in the coal mine
While we were going through our reliability issues and overruns in 2022, there was another example of waste that helped us rethink our approach to costs and how we engineer. In a month we saw 15% growth in our storage utilization. Our customer usage grew also, seemingly due to seasonal usage, and while the numbers weren’t quite lining up, our low observability made us uncertain whether this was a one-off or a larger issue. We then saw another 15% jump the next month, which made it clear there was divergence, and our S3 costs were growing much faster than customer usage.
At the time, our system was designed such that our storage layer, Storm, was pure storage: it understood files and groups of files but none of the business logic around them. Internally, it would store files as blocks in S3; rather than storing as files or using EBS, our storage client broke apart files into fixed size blocks on upload and stored each block as an S3 object, then reassembled those blocks into files on download.
The rest of the service architecture was relatively simple – a Ruby service with an RDS database and a CRD API – transfers were immutable, so you could only create groups of files, read, and delete them. It had no notion of expiration or lifecycle for files – that was the domain of the application layer, which tracked expiration policy and notified the storage layer when it was time to delete.
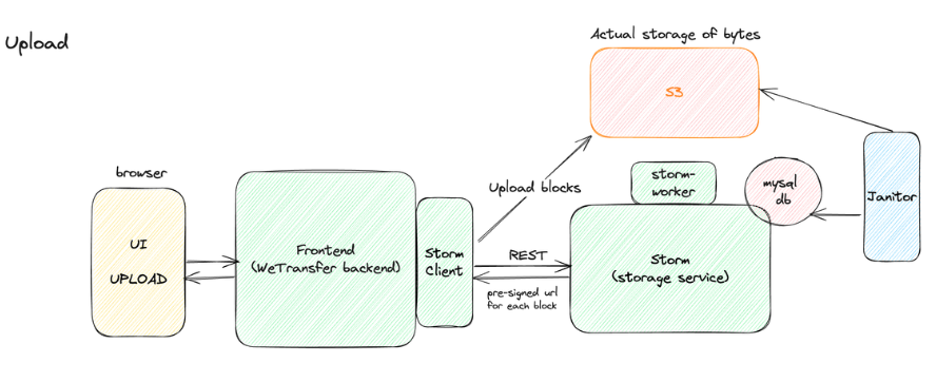
This notification would happen in background jobs that would run twice a day on a fixed schedule. The storage layer would take the deletion requests and hand them to the storm worker, which would remove files in its RDS database and mark blocks for deletion. Storm would then separately run a Janitor cron job twice a day that would query the database for blocks to delete, issue delete calls to S3 in batches to clean up blocks, and finally remove block entries from its database.
As we hit downtime issues due to unrelated problems in the transfer backend, we’d miss the normal background job runs to expire transfers and notify the storage layer to delete files. When the background job ran again, the volume of transfers to expire would be 2-3x the normal size. Given how our service had scaled since our storage layer was originally built and deployed, the janitor was now handling 4-6x the deletion volume at a time.
In the long list of places where lack of observability made our past life harder, at the top was not having any tracing in place to see the storage janitor was running out of memory daily. It was silently crashing while trying to run an SQL query for a much longer set of pending deletes and retain them in memory, and as a result we were failing to delete blocks and accruing waste – blocks no longer referenced by any files or transfers that nobody needed anymore in S3. After the janitor crashed, it would then try to run again, and hit the same exact issue.
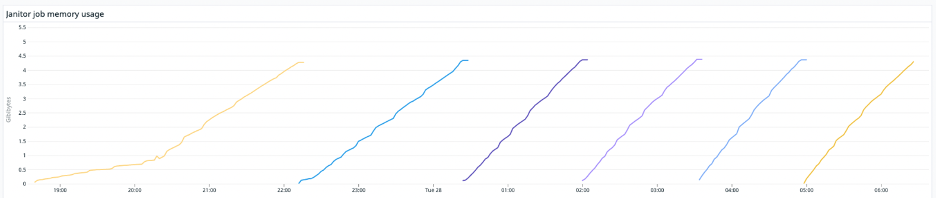
We had missed this as our use case grew – simple queries that were built around much smaller cleanup tasks that could be fully contained in memory, resource reservations that expected a few GB of memory would be enough, a retry pattern that would hit the same barriers and cause the job to fail the same way every time.
Once we had overcome the lack of observability and the pressure of overrunning costs, and understood what was going on, the immediate workaround was straightforward. We raised memory reservations by 20x so the cleanup tasks would hopefully complete every day. This bought us time, with some manual intervention at times as we identified memory leaks and failure points.
The long-term solution – the one that didn’t just rely on the cloud to scale up resources – took a bit more planning. The janitor was redesigned to run in smaller chunks at a time and to execute more often. As a company we were starting to adopt Go, and over the years we had seen memory leaks crop up in Ruby internals, so we took this opportunity to rewrite the janitor in Go. We also added better monitors, which allowed us to see the 90% reduction in CPU and memory use realized from our new approach.
While doing this, we also had to build and run a multiple-day task to delete the 2.3 billion blocks that had been leaked along the way – by that time almost 40% of our overall S3 use.
Closing thoughts
It’s impossible to write these stories without some level of embarrassment. How could this have happened? The reality is of course these types of issues would happen. Choices were made for problems in the moment. In the absence of controls and monitors the focus was never on waste or costs, it was on scaling up and solving the next problem. The talented people we hired, many who had worked at much larger companies previously with proper controls in place, had to focus on scale. We hadn’t yet set the mindset, measurement, and goals to make progress on cost and sustainability. It takes time to build culture - setting intention, finding success, and building on it - and we hadn’t started that journey. It is a story you can see in many companies going through a scale up. You focus on the problems immediately in front of you and take the risk of the unsolved problems – the trail of destruction – that you are leaving in your wake.
You do this because the next milestone for your company is existential. Launch the next feature and hit the milestone before your funding runs out. Sort out your availability issues before your customers abandon your product. Get your fast follow feature out before the trial period expires. The origin story of software companies today is rooted in focus on the next step and worry about the rest later. When running this way, things aren’t important until they are.
Working from that place – the state we started in 4 years ago – may sound painful. In practice, it was a journey we started by taking steps. Establishing a mindset. Reviewing with outside support. Adding observability so we could monitor and learn about our costs and impact. Using costs as a proxy for carbon impact. Identifying modest but impactful benefits – wins – that we could use to build momentum. All of these investments helped people on the team see places where they could have impact towards our company goals on carbon. Our consistency on this over time allowed us to develop the culture and the dialog around digital waste and sustainability internally.
There is nothing unique about where we started. Our journey wasn’t that unique either, and the technical details of the issues we uncovered over the years really aren’t that complicated. The need for observation of costs is well understood, and there are many more tools available to you now, if starting new, to start with the right monitors in place.
But if you aren’t starting from scratch – if you find yourself with a large production system, delivering a successful product in a healthy business, and you realize you don’t have enough information to know what drives your costs, know that progress is achievable. You don’t have to stop work and rebuild from scratch or refocus the entire team on cost savings to make progress. Slow and steady investment in observing our costs has led to some of our biggest wins.
In this way, the coming waves of cost consciousness and sustainability are much more approachable than the past waves I’ve seen of security, privacy, and accessibility where incremental progress wasn’t enough. With cost, and with carbon impact, 10% here and 30% there add up quickly. Progress matters more than perfection. At WeTransfer, the progress we made allowed our business to grow while our infrastructure costs stayed relatively flat. Not through massive rewrites, or from hard pushes to peak efficiency in everything we did, but from investing in reducing digital waste and celebrating our wins along the way.
We did this as we continued to validate that our investment in cost reduction accrued to our additional goals around reducing our carbon impact. We pushed for improvements in emissions reporting and provided reporting to our partners and customers, so they understood the impact of working with us. We spent years on this journey and there were more years ahead. Every year we saw both progress worth celebrating and the opportunity to ask ourselves what more we could do.