Watch Duty was born out of necessity and frustration. In 2020, co-founder and CEO John Mills moved to Healdsburg, CA and quickly realized the realities of living in a fire prone area. He found that critical wildfire information was scattered or missing — some people monitored radio traffic, others relied on community Facebook groups, and there was no single, reliable source. Recognizing the need for accessible, real-time updates, John had a simple but powerful idea: give the people already reporting on wildfires a purpose built platform to this end.
John and I met almost fifteen years ago, my first boss and mentor as I accidentally stumbled backwards into software after moving to San Francisco. It turns out if you are writing perl scripts to automate your data entry job, they realize you might be working on the wrong side of the company. We quickly became friends and have either been having fun and/or working on things together since. So when I was visiting John for a weekend trip, and he started describing his newest idea, I listened closely.
John quickly convinced me that this was worth doing. I’d dabbled in my own social good projects, and had previously found work aligning myself with a mission based focus, but in this idea was the rare combination of an idea that was sorely needed with an MVP that was so eminently doable. John’s excitement for this idea was contagious, and soon we had a group of volunteers to see what would come of a good idea. Watch Duty was born, blending the structure and approach of a tech startup with the mission driven spirit of a non-profit. I started with an initial technical requirements doc, we revved on that a few times, and we were off to the races. John was the only person without a job, and he held the torch, working his own full time job on this project, and the rest of us joining in, PRs going back and forth faster than I could keep track of from the side. And in eighty days, Watch Duty launched to four counties in Northern California. By the end of that fire season, with almost 100,000 users and overwhelming community support, it was clear that John’s personal frustration and need for better information was shared by the broader public.
Starting simple
The development of Watch Duty is a story of constraints. Constraints on money, people, but most of all – constraints of timeliness and stability. In a fast moving wildfire, every second counts, and reliability and timeliness for this volunteer led project would be paramount. We had a simple goal with our MVP of Watch Duty: notify users about new wildland fires and changes in fire conditions with contextual information on a map (and that mission hasn’t really changed). When starting something new, there’s always the temptation to try the “shiny new toys” - learn a new javascript framework, try out a new database you haven’t used before, new API framework or servless services - things you’ve read about and done little projects with but never used in a production or work setting. Despite my initial desire to expand my toolset and learn new things, I took a breath and thought what problem am I trying to solve? What technologies/approaches am I and our volunteers productive with that will allow us to move quickly and build something reliable. Instead of a new web framework, we picked Django (again). Instead of serverless or Kubernetes, we picked Heroku (again), and instead of some new global scale database provider, we picked MySQL on RDS (again).
We based these decisions on a few guiding principles: stability, ease of development and operations, and scalability for large surges in traffic. We knew enough about Watch Duty’s future usage to know it would be critical in a way that B2B software rarely is. That we’d have long periods of low traffic with large spikes in traffic as an impactful fire started.Little did we know back then that in a few short years we’d have 9 million unique visitors per week or handling 100,000 requests per second.
These boring choices have served us well. The initial constraints on time and resources made sure we’ve had a solid foundation to grow from. Python made it easy to onboard new engineering volunteers and later supported the geospatial analysis we needed to improve the product. AWS, Heroku, and New Relic minimized infrastructure maintenance, letting us focus on operations. Capacitor allowed our tiny team to quickly build and maintain feature parity across web, iOS and Android with a shared codebase. React allowed us to take advantage of a wide library ecosystem and onboard new volunteers quickly.
Maturing as necessary
By the end of the first fire season, we knew that Watch Duty had product-market fit. Our name appeared on firehouse signs, we received great feedback from our users, and a significant portion of the population in our coverage area had installed our app - all with zero marketing. Our next step was clear: expand to cover all of California and the Western US. However, this was going to require some technical changes.

Fortunately, we never had to rip out or replace our core architecture. Our decision to keep things simple worked in our favor. Instead, we could focus on strategic improvements: investing in geospatial tooling, refining caching techniques for massive traffic spikes, and even decoding analog DTMF signals from radio-waves to improve early fire detection. Because we started small, we had the luxury of delaying decisions until we could better understand the technologies and capabilities that best solve these problems.
I think a common thread for our engineering decisions over the past few years has been, “How far can we go with what we’ve got?” This approach helped us with our initial engineering resource constraints and continues to help us now with a codebase and architecture featuring minimal bloat. As our engineering team starts to grow, we’ve finally got a little breathing room to take on more complexity - like running our own GIS tile servers - and the expertise to develop more mature solutions. That period of time with what could be considered “suboptimal” solutions let us learn about where our product is heading, what technical capabilities will enable future growth, and about our scaling characteristics. We never could have made the choices we are now making four years ago. There is an art to starting with simple, effective solutions and then knowing when they have to mature.
The challenges of API caching
One of our biggest technical challenges has been around scaling and API caching. Our traffic occurs in large sudden bursts. A new fire starts in a heavily populated area, and suddenly 100,000, 250,000, or in the case of LA, 2.5MM users all pick up their phones in and around the same one minute period. Most of our traffic does not vary by user, which is great for caching. But at the same time, we can’t afford to have stale content served. If someone gets a push notification saying the fire has just grown to 100 acres and it says 50 when they open the app, we’ve lost that user’s trust, and possibly given them unsafe information.
Initially, we considered in-memory caching with Redis at the Django API level but realized we needed to stop traffic before it reached our app servers. Auto-scaling is too slow for these types of bursts, so we either need to overprovision all the time (also part of the answer) or stop the traffic before it gets to our API. We settled on CloudFront, leveraging a creative approach. Most traffic during these periods came after receiving a push notification, and we realized that by coordinating a cache-busting URL parameter through this shared data (the push notification payload contained a consistent timestamp), we could have all users get the same set of fresh data with a high cache hit rate. This added some complexity to the client, but it was a great step towards smoothing out our traffic spikes - and it was cheap! Since these were small JSON payloads, CloudFront pricing was almost negligible relative to the value we were getting.
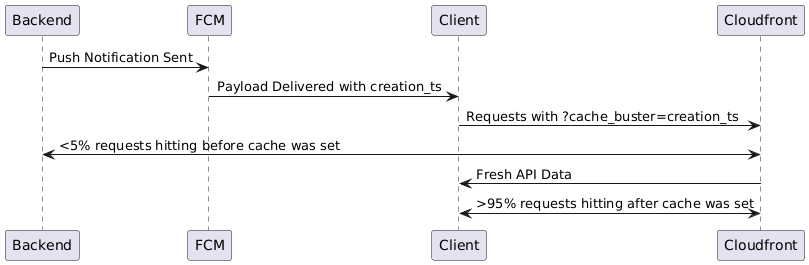
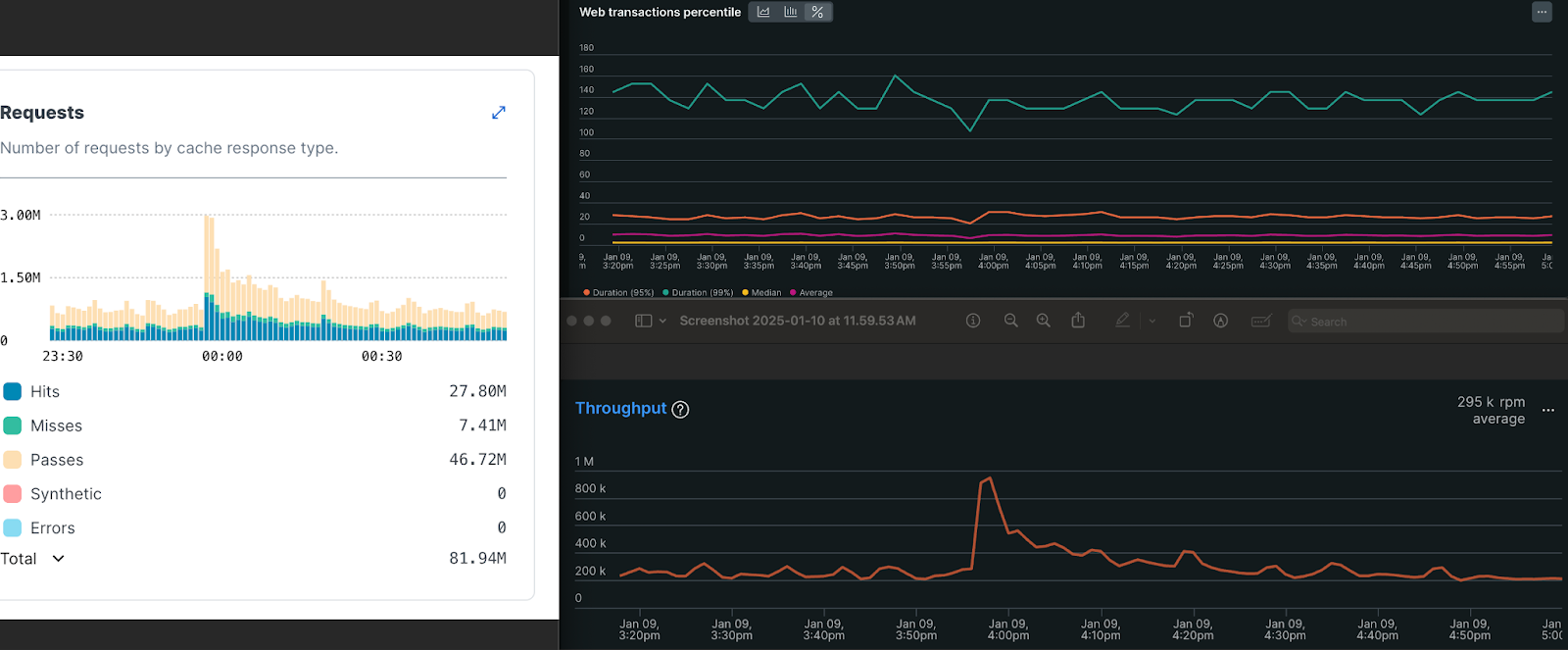
As we started to grow and users had more reasons to stay in the app, traffic started to stay high in between those push notifications. We had more layers on the map to take into consideration, like live wildfire cameras the public can follow along with to track fires with, and session length started to push out. Combined with lack of control over the client side grouping approach, these made us start looking for a more flexible option. We ended up going with Fastly—again, a more mature, complex (and expensive) solution—but now the decision was made with a deeper understanding of what we needed. Fastly offers global purges on their CDN network in <150ms, which allows us to cache dynamic content with a high level of granularity and flexibility. We started the implementation process, placing essentially a passthrough layer in front of our API at the end of 2024. And just in time, as it worked out. As the January 2025 fires in LA started, suddenly we had 10x traffic from our previous peaks in 2024. And although I had imagined taking a more measured approach during low traffic periods, suddenly we were “doing it live,” implementing a new caching strategy which ended up reducing nearly 80% of our backend traffic during those peak times.
Advancing our geospatial capabilities
A similar progression occurred in our approach to geospatial assets. Our platform started very bare bones: just a base map layer and icons for fires. We soon realized how impactful the concept of consolidating all the tabs (bringing all external data sources that the public or reporters use into our application) could be for increasing the context people had while making life-critical decisions. Most of these other data sources were geospatial, starting with wind and satellite heat detection, moving on to active fire perimeters and evacuation zones and a host of others. These existing data sources were managed by third parties, oftentimes in a public ArcGIS service, so that’s where we started.
We realized a host of challenges we were going to face with surfacing external GIS data. Many of the data sources were in an inefficient GeoJSON format, which is both slow to download and render on mobile devices. This was particularly problematic for our user base which skews rural, many of whom rely on limited cellular connections and older devices during emergencies. And with 90% of our users on mobile, slow downloads were a non-starter–people facing evacuation decisions can’t wait minutes for map data to load. We also realized we had a much higher standard for the quality of data. We could internally verify the data on sources like fire perimeters but didn’t have a good way to remap or clean them when we weren’t publishing them ourselves. From these two use cases, we knew we would need a way to publish our own geospatial assets, whether that was a simple conversion from GeoJSON to vector tiles, or a more involved ingestion → verification → republication process.
We ended up choosing Dagster to run our geospatial data pipelines. With their cloud offering providing immediate CI/CD/Hosting, all we had to do was write some Python code. We now had a platform where we could observe, orchestrate, and process any external data and improve it for our product (again, at a very good value considering what it would have cost us to build and maintain something similar internally). We started simple, publishing vector tiles as files to S3/CloudFront combinations, and using a combination of internal ETL and ArcGIS Online to handle the immediate verification/republishing needs.
We’d started scrappy with our simple initial implementation, and that bought us time to work out the kinks with real users and better understand what their needs were going to be and how we could best solve them. What we realized over time was that geospatial data was a critical capability for us, not just as static assets, but for operationally critical data. We ran into growing pains with our initial implementations that helped us understand what a better technology capability would look like.
We evaluated our options and went with a new Postgres + PostGIS instance + Martin vector tile server for our now dynamic and internally mapped geospatial data. This handled several things:
- The challenges of partial updates (not really possible for vector tiles as static blobs)
- Data coordination between things like semi static evacuation zones and the individually toggled evacuation zone statuses
- Approval/validation like processes are now entirely in house
- Enabling a whole new set of product features that can be built “with the right tools”
Sometimes you have to build it yourself
The most critical aspect of Watch Duty’s reporting (responding to new wildfire starts and updating the community on their behavior) is driven by reporters listening to digital rebroadcasts of local fire service radio transmissions. But as we expanded, we discovered large dead zones where no reliable scanner feeds existed, limiting our ability to cover fires in certain regions. What has started as a small project has morphed into a critical portion of our ability to report on fires, with over 15 deployed hardware installations of our echo boxes and many more planned.
And past this, the radio scanner feeds we were listening to with the echo boxes contained DTMF and QC2 tones - think the noises you heard when dialed a land line - representing dispatches between dispatch centers and firehouses. Beep-boop-boop meant 3 dozers and 4 fire trucks, and Beep-beep-boop meant just 2 dozers (gross oversimplification). The challenge was that these tones meant different things in every county and dispatch center, so we had to create our own yellow pages for these tones for each area.
These innovations—entirely volunteer-driven—underscore our belief that great solutions don’t always come from the engineering team alone. We actively encourage contributors from all backgrounds to bring new ideas that push Watch Duty forward. We still accept applications for new software engineers here.
If you’re curious about the nitty-gritty details of how we tackled the DTMF tone detection challenge, our team wrote a whole blog on it.
What comes next
We are entering a new phase. We have an actual team of engineers! We have QA! We have [some] financial resources! And while wildfires will always be our core focus, our broader mission is helping the public make informed, life-critical decisions while navigating disasters. That’s why we didn’t call it “Fire Watch”.
We aren’t going to solve every problem in emergency response, we are not hydrologists, we’re not going to replace NOAA, and the exact product we created for wildfires won’t fit other natural disasters. But as we look at what exists, there is a gap that we believe we can help fill: world-class product and engineering provided for the public benefit at no cost to the public, to governments, to first responders and aid workers of all walks.
We believe that the public will make better decisions with more information, not less. Each person’s situation is unique, and the current approach to disseminating information during disasters tends towards too little too late. We want to enable every person to make the right decision for themselves, whether that is to hunker down and prepare, go help their neighbors, evacuate, or anything in between. The government has an essential role in all of this, but we want to complement official resources and provide product-driven solutions that are best built within a smaller and more agile organization.
I am incredibly proud of what we’ve built so far at Watch Duty and excited for what is still to come. If we keep making smart choices, based on technology fundamentals and keeping complexity constrained to where it’s needed, we’ll be able to keep delivering outsized impact for our customers, the public.